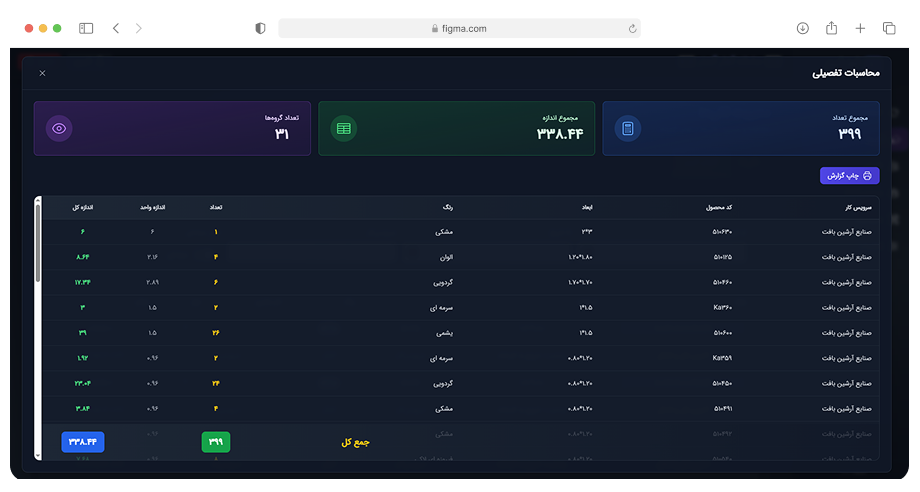
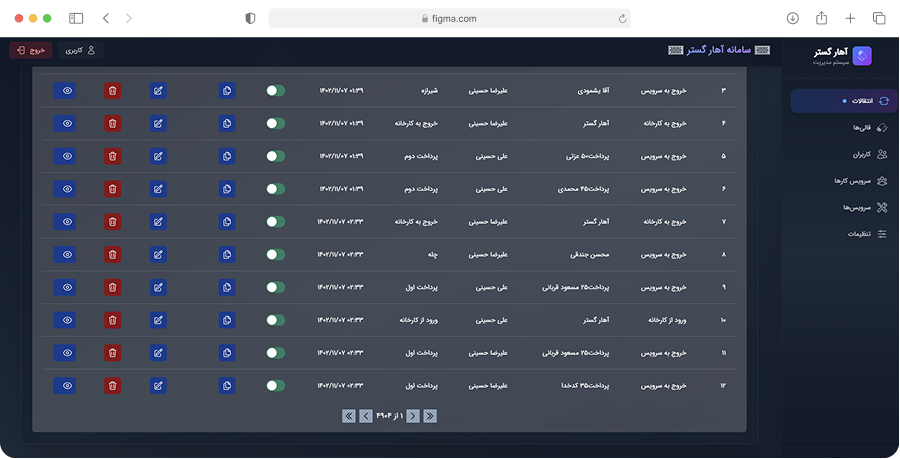
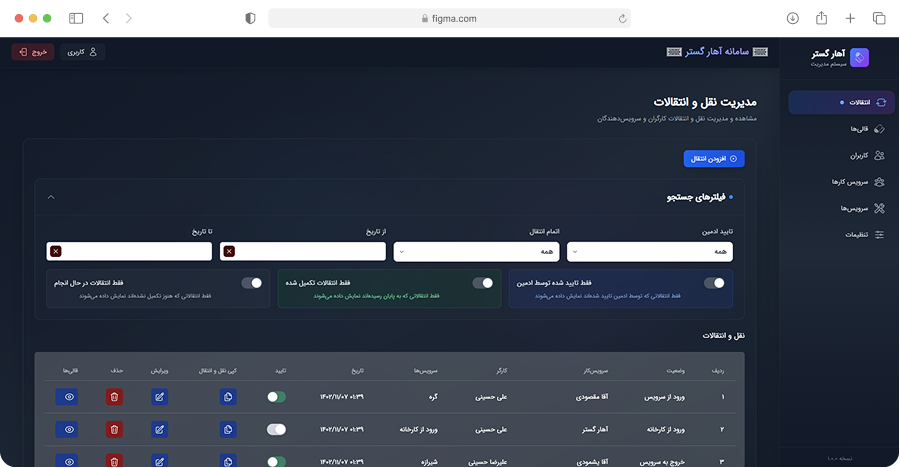
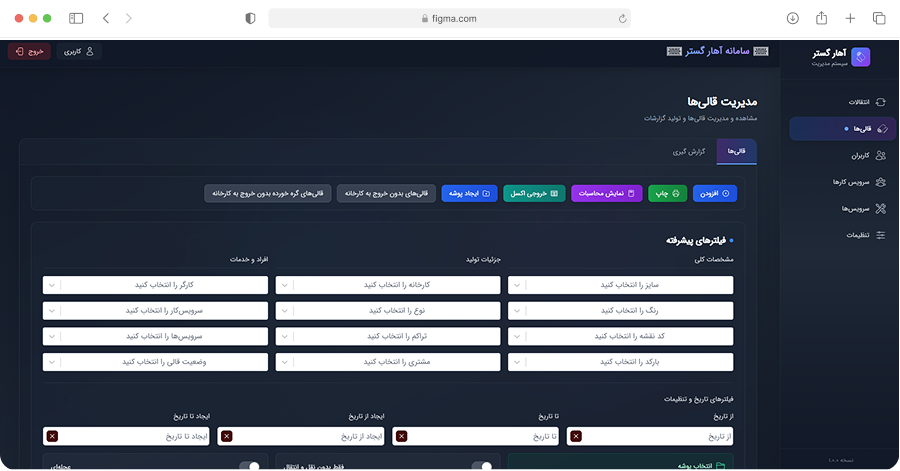
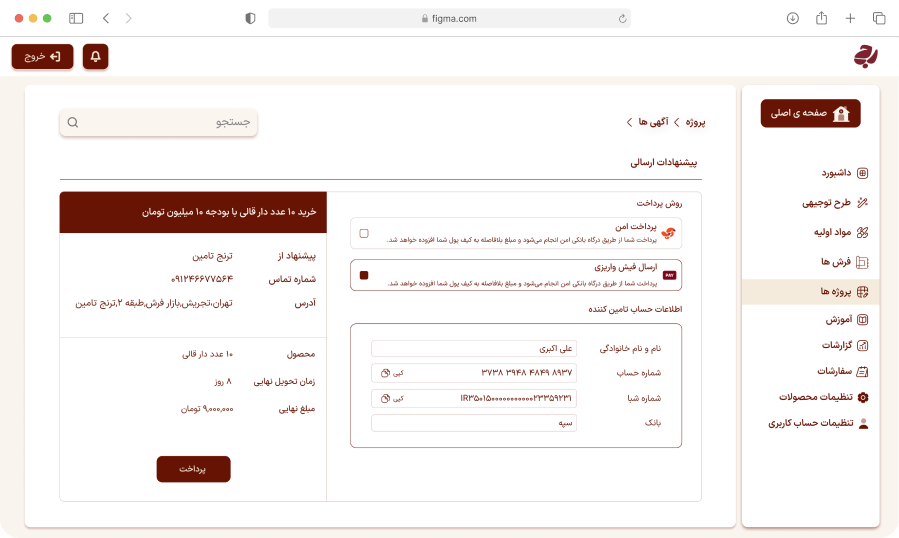
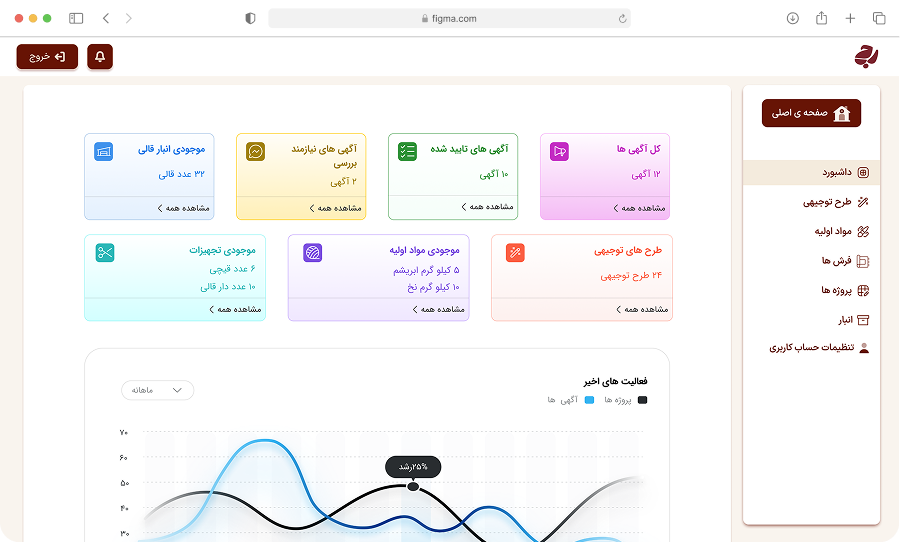
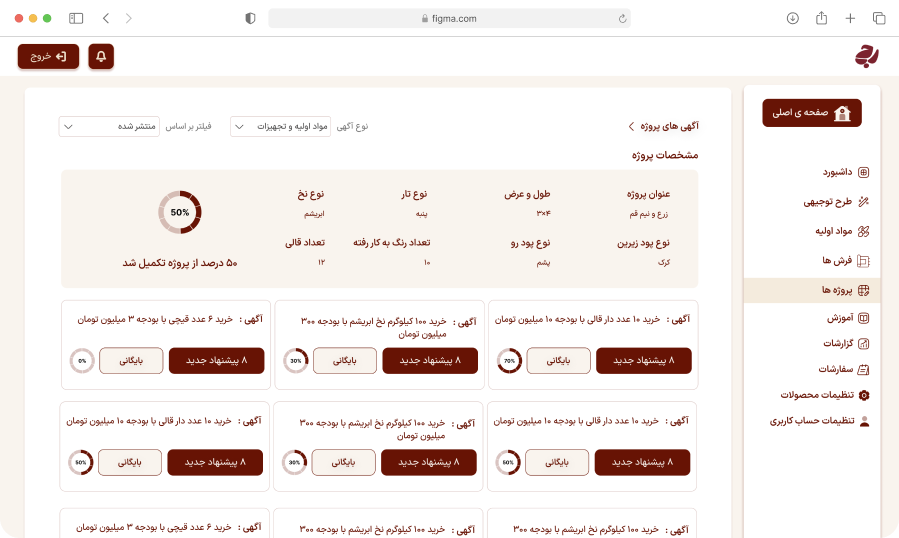
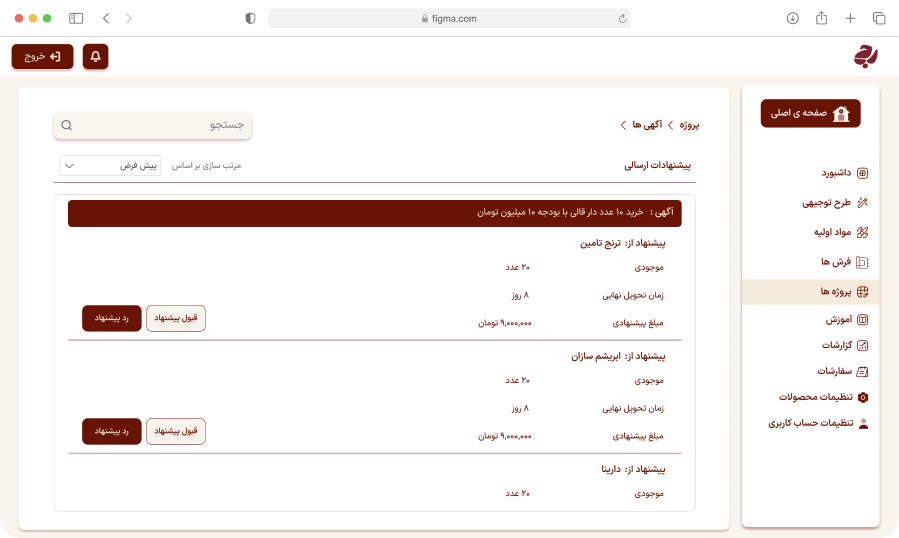
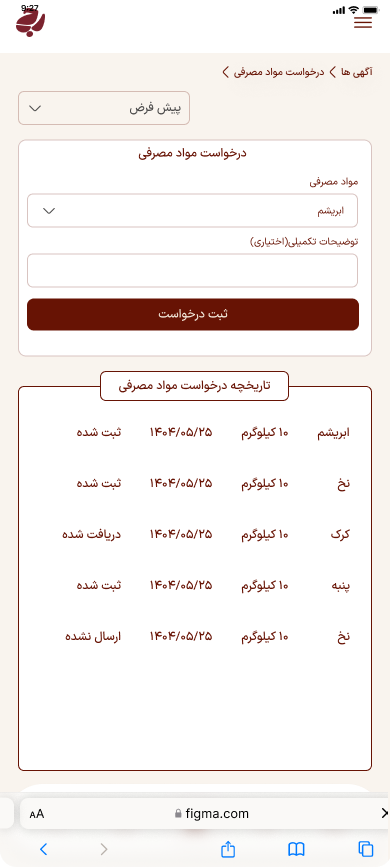
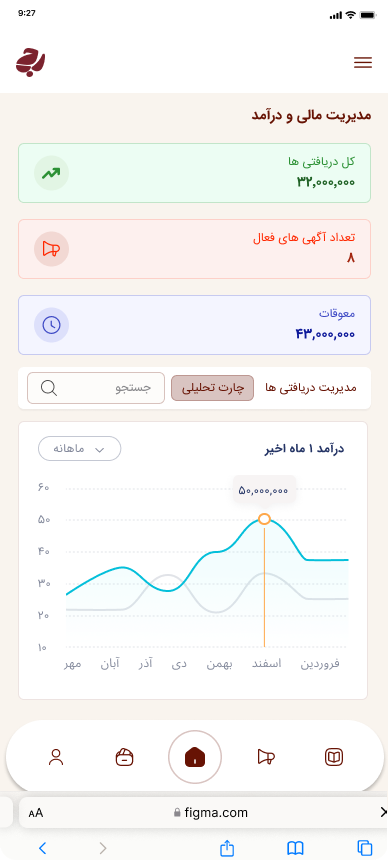
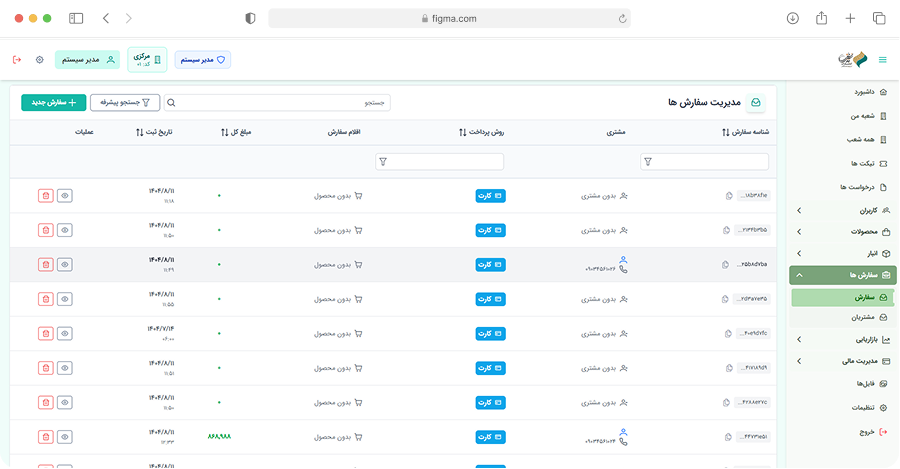
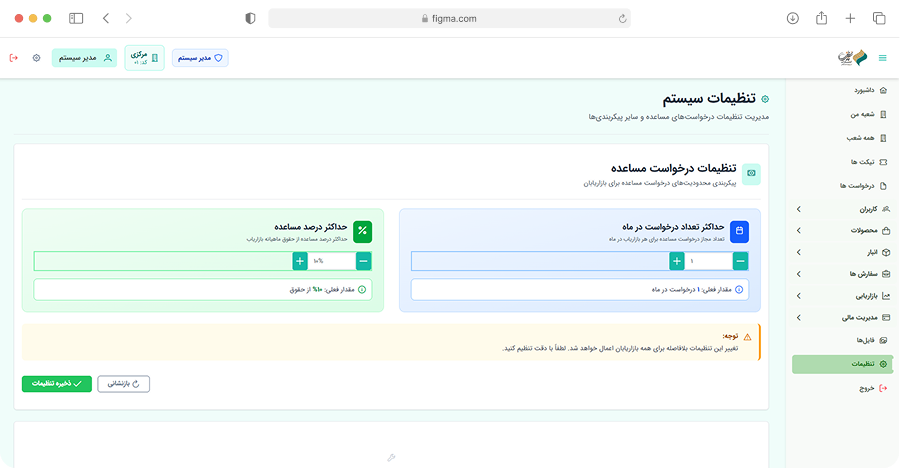
ما دادههای ساختیافته و آمادهی تحلیل را از وبسایتها، فروشگاهها، شبکههای اجتماعی و APIهای عمومی/خصوصی استخراج میکنیم. راهحلها قابل برنامهریزی، مقیاسپذیر و سازگار با نیازهای تحلیلی شما هستند.
آنچه تحویل میدهیم: اسکریپتها یا سرویسهای کراولینگ (یکباره یا زمانبندیشده)
استخراج از صفحات HTML، APIها، فایلها (CSV, Excel, PDF) و شبکههای اجتماعی
پردازش و پاکسازی داده (normalization, deduplication, parsing)
ذخیرهسازی در فرمتهای متداول (CSV, JSON, Parquet) یا ارسال به پایپلاین شما (S3, FTP, DB)
مدیریت پروکسی، چرخش آیپی، و ارسال درخواستهای انسانینما برای عبور از محدودیتها
هندلینگ CAPTCHA و راهکارهای قانونی/اخلاقی (پایبندی به robots.txt و قوانین سایتها)
گزارشگیری و مانیتورینگ کراولها + هشدار خطا